Cloudflare Browser Run vs Firecrawl for AI free tools
If you are building an AI free tool that scans websites, this is the tradeoff: Firecrawl gets you moving faster. Cloudflare Browser Run gives you more control when cost and output quality start to matter.
The useful rule is simple:
| Your constraint | Better default |
|---|---|
| You need a prototype this week | Firecrawl |
| You need clean page text for an LLM | Firecrawl |
| You need cheap browser execution at free-tool volume | Cloudflare Browser Run |
| You need rendered evidence, visible UI labels, retries, validation, and fallbacks | Cloudflare Browser Run |
That is what happened with the Agent Analytics Product Growth Scanner. We started with the higher-level path, then moved lower when the browser layer became part of the product.
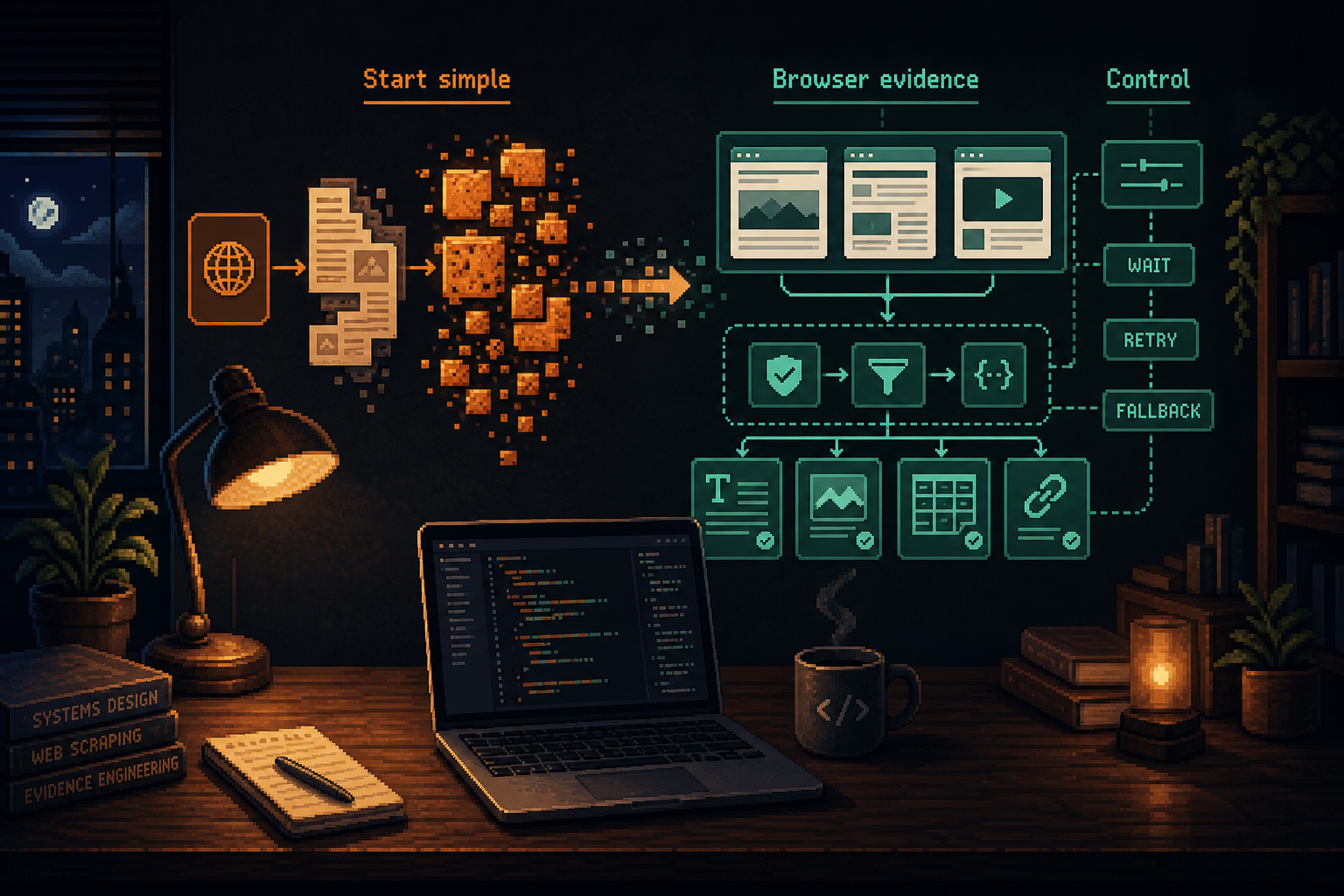
The scanner needed evidence, not summaries
A generic website summary was not enough.
The scanner needed to answer sharper questions:
- What buttons and paths are actually visible?
- What proof, pricing, install steps, and forms are on the rendered page?
- Which three events should the founder track first?
- Which experiment ideas are tied to real page evidence?
- When is the model making generic CRO filler instead of reading the page?
Once those became product requirements, the crawler was no longer plumbing.
What we ended up implementing
The current scanner is Cloudflare-only.
In agent-analytics-hosted/hosted/website-scanner.js, provider resolution accepts:
| Mode | Provider | What it does |
|---|---|---|
| Preview | cloudflare_workers_ai |
Browser Run gets rendered markdown/content, then Workers AI turns page facts into the scan. |
| Full | cloudflare_browser_ai |
Browser Run /json with the full scanner schema. |
| Fallback | deterministic code | If the AI pass gets weak, build events and tests from extracted page facts. |
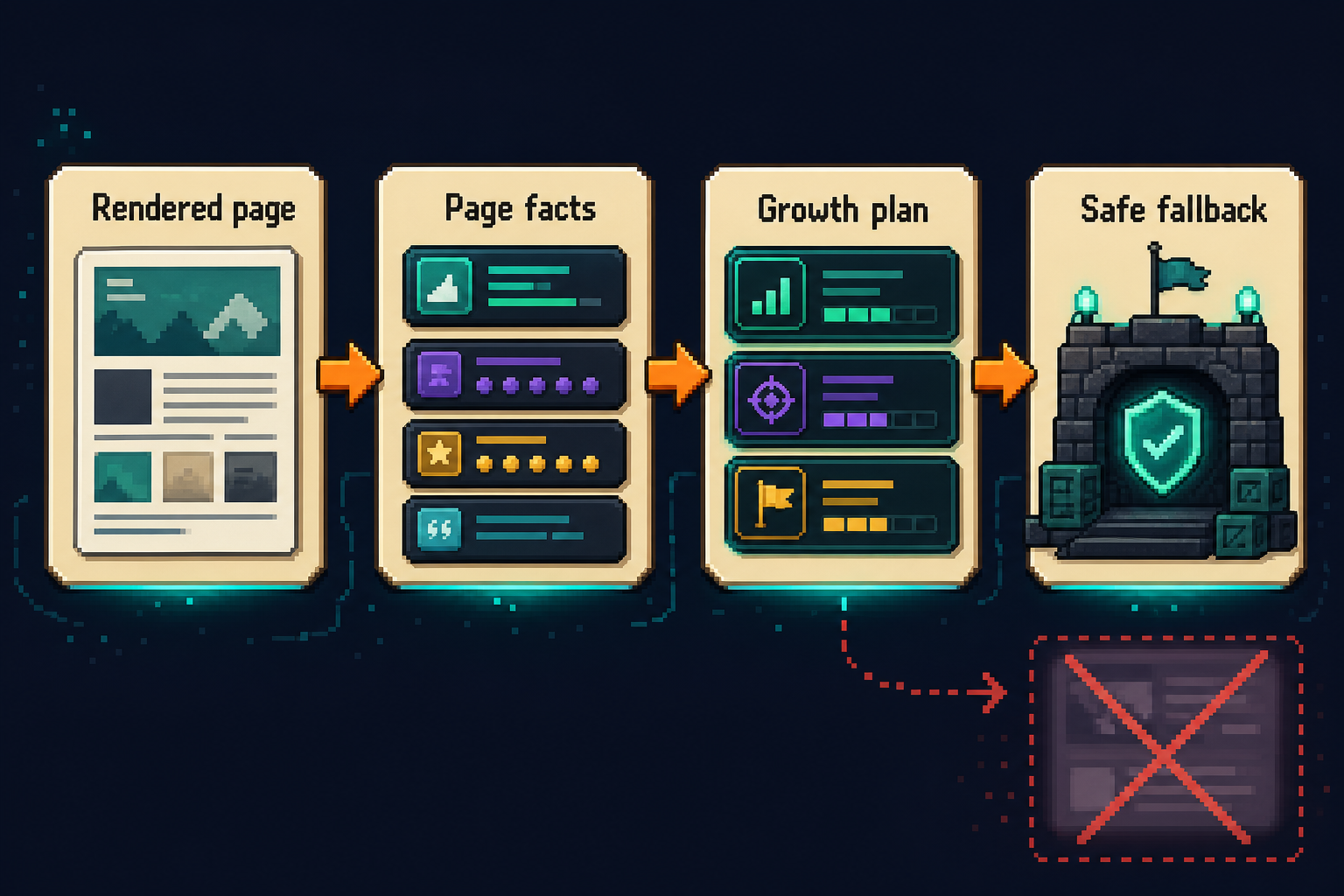
The preview path is the important one:
- Browser Run gets the rendered page through
/markdown. - If needed, it retries through
/content. - The scanner extracts page facts: offer, buttons, paths, forms, proof, onboarding, install commands, pricing hints.
- A second AI pass turns those facts into events, blind spots, and experiment ideas.
- Validation rejects output that is schema-valid but not grounded in rendered evidence.
- Deterministic fallbacks produce a safer result from actual labels.
That is the real product improvement. Not “Cloudflare is cheaper Firecrawl.” More like: Cloudflare let the scanner become evidence-first.
Why Firecrawl lost this use case
Firecrawl is still the better starting abstraction when you need clean extraction quickly.
It lost here because the scanner became a free acquisition surface. Every scan has a budget. If cost makes you nervous about usage, you will under-build the tool.
And once the scan quality depended on exact visible evidence, convenience mattered less than control over:
- rendered page evidence
- exact visible labels
- retry behavior
- validation gates
- generic-output rejection
- deterministic fallbacks
Cloudflare was more setup. It also made the result more specific.
My rule now
Start high-level while the product question is fuzzy.
Move lower-level when the extraction layer becomes part of the product.
For this scanner, Firecrawl helped the idea move fast. Cloudflare made the output better and cheaper to run. That was the right trade.